In today’s digital age, data is the new currency. Businesses are constantly collecting and analyzing vast amounts of data to gain insights, make informed decisions, and stay ahead of the competition. However, with the ever-increasing volume, variety, and velocity of data, traditional data storage and processing methods have become inadequate. This is where data lakes come in.
Data lakes are centralized repositories that store raw, unstructured, and structured data at any scale. They provide a cost-effective and scalable solution for storing data, making it accessible for analysis and processing. In this blog, we will dive into the architecture and components of a data lake, and how they work together to create a robust data management system.

A data lake is a storage repository that holds a vast amount of raw, unprocessed data in its native format. Unlike traditional data warehouses, data lakes do not require data to be structured or predefined before ingestion.
This means that data can be stored as-is, without the need for any transformation or schema. This makes data lakes highly flexible and accommodating for storing any type of data, whether it be structured, unstructured, or semi-structured.
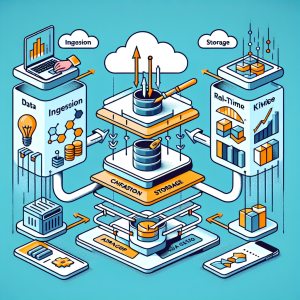
The architecture of a data lake is made up of several components that work together to store, manage, and process data. The three main components of a data lake architecture are data ingestion, data storage, and data processing.
**Data Ingestion:** The first step in the data lake architecture is ingesting data from various sources. These sources can be internal systems, cloud services, or external data providers. Data ingestion is typically done using tools like Apache Kafka, Apache NiFi, or AWS Kinesis. These tools help to collect, filter, and route data to the data lake.
**Data Storage:** Once the data has been ingested, it is stored in the data lake. Data lakes use a flat architecture, where data is stored in its native format, without any transformation or schema. This means that data can be stored in its raw form, making it easily accessible for analysis. The data storage layer of a data lake is typically made up of a distributed file system, such as Hadoop Distributed File System (HDFS) or Amazon S3.
**Data Processing:** The final step in the data lake architecture is data processing. This involves transforming and analyzing the data stored in the data lake to gain insights and make informed decisions. Data processing can be done in two ways – batch processing or real-time processing. In batch processing, data is processed in large batches at regular intervals, while in real-time processing, data is processed as soon as it is ingested. Popular data processing tools used in data lakes include Apache Spark, Apache Hive, and Amazon EMR.

Apart from the three main components mentioned above, there are several other components that make up a data lake architecture. Some of these components are:
**Metadata Store:** A metadata store is used to store information about the data stored in the data lake. It includes the data’s source, creation date, format, and any other relevant information. This metadata is crucial for data governance, data lineage, and data discovery.
**Data Catalog:** A data catalog is a central repository that contains information about all the data stored in the data lake. It helps users to easily discover, understand, and use the data available in the data lake. Data catalogs can be self-service or curated, depending on the organization’s needs.
**Data Governance:** Data governance is the process of managing and controlling data to ensure its quality, accuracy, and security. In a data lake, data governance involves defining policies, procedures, and standards for managing data, along with implementing security measures to protect sensitive data.
**Data Quality:** Data quality is the measure of the accuracy, completeness, and consistency of the data stored in the data lake. Data quality tools are used to monitor data quality, identify any issues, and ensure that the data is fit for use.
**Data Security:** Data security is essential for protecting sensitive data stored in the data lake. It involves implementing access controls, encryption, and other security measures to prevent unauthorized access to data.
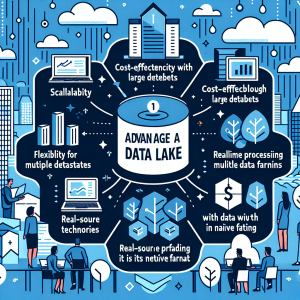
Data lakes offer several advantages over traditional data storage methods, some of which are:
– Scalability: Data lakes are highly scalable and can accommodate any amount of data, making it ideal for organizations with large datasets.
– Cost-effective: Data lakes are typically built on open-source technologies, making them cost-effective compared to traditional data warehouses.
– Flexibility: Data lakes can store any type of data in its raw form, making it ideal for storing data from multiple sources and formats.
– Real-time processing: With data lakes, real-time processing is possible, allowing organizations to gain insights and make decisions in real-time.
– Data discovery: Data lakes store data in its native format, making it easy to discover and use for analysis.

While data lakes offer many advantages, they also come with their own set of challenges, such as:
– Data governance: With data lakes, there is a risk of data becoming ungoverned, leading to data quality issues, security breaches, and compliance violations.
– Data silos: Without proper data governance, data silos can form within the data lake, making it difficult to integrate and analyze data.
– Data quality: With data lakes, there is a risk of poor data quality, as there is no predefined structure or schema for data ingestion.
– Data security: As data lakes store data in its raw form, there is a risk of sensitive data being exposed, making data security a top concern.
Data lakes are becoming increasingly popular among organizations looking to store, manage, and analyze vast amounts of data. With its flexible architecture and scalable nature, data lakes offer a cost-effective and efficient solution for data management. By understanding the architecture and components of a data lake, organizations can build a robust data management system that meets their unique needs. However, it is crucial to address the challenges that come with data lakes to ensure the data is governed, secure, and of high quality.


